This article explores NQE's robust pattern matching for extracting and parsing data, simplifying complex tasks with high-level, well-defined types for reporting and evaluation.
Approach 1: Leveraging the “or” pattern as described here
Using the following pattern
`ntp server {"vrf" vrf:string server:string | server:string}`;
We can accommodate various patterns for this command syntax by which the literal “vrf” and the VRF name maybe elided from the command. Instead of needing to create two separate patterns we can combine them into one expression.
Looking closer at how we then extract the properties out of the data for vrf and server. The expression will append all properties to the left of the ‘|’ pipe operator to the data.left property and will append all properties to the right of the ‘|’ pipe operator to the data.right property. We simply then just test for the presence to property to determine which properties to extract.
The purpose of the below expression is to create a union record-type such that we can combine both cases with the exact same properties and types.
let ntp = if isPresent(data.left) then { vrf: data.left.vrf, server: data.left.server, command: match.line.text } else if isPresent(data?.right) then { vrf: "", server: data.right.server, command: match.line.text } else { vrf: "", server: "", command: match.line.text }
Approach 1 Test
// Setup our testing tests = ["ntp server vrf MGMT 1.1.1.1", "ntp server 1.1.1.2"];
pattern1 = `ntp server {"vrf" vrf:string server:string | server:string}`;
getNtpServers(matches) = foreach match in matches let data = match.data let ntp = if isPresent(data.left) then { vrf: data.left.vrf, server: data.left.server, command: match.line.text } else if isPresent(data?.right) then { vrf: "", server: data.right.server, command: match.line.text } else { vrf: "", server: "", command: match.line.text } select ntp;
foreach device in network.devices where device.platform.vendor in [Vendor.ARISTA, Vendor.CISCO] // Run through each test, this would be removed in production foreach test in tests let m = patternMatches(parseConfigBlocks(OS.UNKNOWN, test), pattern1) // End of testing // let m = patternMatches(device.files.config, pattern1) let ntpServers = getNtpServers(m) select { violation: length(ntpServers) == 0, device: device.name, server: (foreach s in ntpServers select s.server), command: (foreach s in ntpServers select s.command) }
Approach 2 : Unifying multiple patterns
Sometimes we have text that we can’t really combine as we did in Approach 1 because the order or is quite different. This can happen when trying to unify common state information across different vendor outputs as seen below.
You can see while the content is similar the order of the fields are different.
testIOS = """ Neighbor ID Pri State Dead Time Address Interface 10.200.30.42 0 FULL/ - 00:00:35 10.45.6.1 GigE1/0/0 10.200.30.42 0 FULL/ - 00:00:32 10.45.6.2 GigE1/0/1 10.200.30.42 0 FULL/ - 00:00:35 10.45.6.3 GigE1/0/2 10.200.30.42 0 FULL/ - 00:00:31 10.45.6.4 GigE1/0/3 10.10.10.200 1 FULL/BDR 00:00:03 10.45.6.5 Vlan200 """;
testEOS = """ Neighbor ID Instance VRF Pri State Dead Time Address Interface 2.2.2.2 1 default 1 FULL/DR 00:00:38 10.1.1.2 Ethernet1 4.4.4.4 2 default 1 FULL/DR 00:00:36 40.1.1.2 Ethernet4
""";
One approach is to utilize multiple patterns than unify them in your top-level function as seen in this example NQE Query to List OSPF Neighbors
But I am going to show you another approach, this is really for demonstration purposes, you might find this technique useful to solve other problems so it is worth understanding.
Above we have two patterns, they are designed to accommodate the specific OS output as shown above. You might notice this pattern {<VAR>:(string | empty)} let me explain what this is doing.
From our documentation
empty always matches successfully and returns an empty record. This pattern is often useful in combination with | pattern builder, because it allows you to indicate an optional argument in a pattern. For example logging {"host" | empty } {ipv4Address} matches commands like "logging host 1.2.3.4" and "logging 1.2.3.4" where the second argument can be "host" or can be omitted.
So what purpose does this solve? if you notice, the Cisco IOS output does not have a column for VRF, but the Arista EOS output does. The reason for using these patterns where they clearly won’t have any effect because they will always evaluate to null is they will unify the record type so they type check properly. this allows the following function getPattern(OS) to work. If we don’t unify the types we will get an error and won’t be able to combine the evaluation into a single list.
getPattern(os) = when os is IOS -> patternIOS; ARISTA_EOS -> patternEOS; otherwise -> patternIOS;
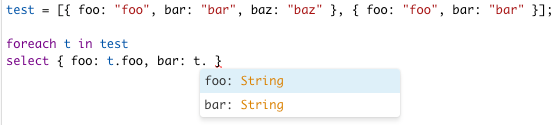
Note: Something to be aware of is that you can have a partially disjoint list such that not all properties exist in each record as seen below. But NQE will only produce the union of these records such that only the common properties will be accessible. In the example below you can see we drop the baz property so it is not available.
Approach 2 Test
testIOS = """ Neighbor ID Pri State Dead Time Address Interface 10.200.30.42 0 FULL/ - 00:00:35 10.45.6.1 GigE1/0/0 10.200.30.42 0 FULL/ - 00:00:32 10.45.6.2 GigE1/0/1 10.200.30.42 0 FULL/ - 00:00:35 10.45.6.3 GigE1/0/2 10.200.30.42 0 FULL/ - 00:00:31 10.45.6.4 GigE1/0/3 10.10.10.200 1 FULL/BDR 00:00:03 10.45.6.5 Vlan200 """;
testEOS = """ Neighbor ID Instance VRF Pri State Dead Time Address Interface 2.2.2.2 1 default 1 FULL/DR 00:00:38 10.1.1.2 Ethernet1 4.4.4.4 2 default 1 FULL/DR 00:00:36 40.1.1.2 Ethernet4
getPattern(os) = when os is IOS -> patternIOS; ARISTA_EOS -> patternEOS; otherwise -> patternIOS;
getText(os) = when os is IOS -> testIOS; ARISTA_EOS -> testEOS; otherwise -> testIOS;
foreach os in [OS.ARISTA_EOS, OS.IOS] let commandText = getText(os) let filtered_response = replace(commandText, "-", "") let blocks = parseConfigBlocks(OS.UNKNOWN, filtered_response) foreach match in blockMatches(blocks, getPattern(os)) let data = match.data select { // Device: device.name, // Platform: device.platform.model, OS: os, Priority: data.Pri, State: data.State, "OSPF Network": data.Address, Interface: data.Interface, VRF: data.VRF.left, Neighbor: data.neighbor_id, Instance: data.Instance.left, DeadTime: data.Dead_time }
Approach 3: Evaluation via token count
This last approach I demonstrated in the post Complex State Parsing and it leverages a technique which chooses a pattern based on how many fields are in the pattern.
For our example lets look at the test harness. Below we have a summarized list of output from a command output. You will notice that the header describes 5 columns but the output can be 5 fields, 4 fields or even 3 fields as not every column in the output is relevant for the item being displayed.
output = """ Hardware inventory: Item Version Part number Serial number Description Chassis JN1096837AFA MX960 Midplane REV 03 710-013698 TR0185 MX960 Backplane PIC 0 BUILTIN BUILTIN 20x10GE SFPP """;
Below are the patterns which describe each of those cases.
So how do we know which pattern to apply when? Well we can leverage the fact that we can determine how many actual fields are there by leveraging a simple function
When we apply this function to the line it tells us exactly how many strings exist in the line, we can then use this with our conditional operators to choose the correct pattern as in the normalizeBlocks function below.
normalizeBlocks(blocks) = foreach line in blocks let var_count = findTokenCount(line) select if var_count == 3 then patternMatch(line, pattern3) else if var_count == 4 then patternMatch(line, pattern4) else if var_count == 5 then patternMatch(line, pattern5) else null : {item: String, serialNum: String, description: String};
Approach 3 Test
output = """ Hardware inventory: Item Version Part number Serial number Description Chassis JN12345837AFA MX960 Midplane REV 03 710-013698 TR01111 MX960 Backplane PIC 0 BUILTIN BUILTIN 20x10GE SFPP """;
flattenBlocks(blocks) = max(foreach x in [0] let matches = patternMatches(blocks, pattern3) let a = (foreach match in matches select stripSpaces(match.line.text)) let b = (foreach match in matches foreach child in match.line.children select stripSpaces(child.text)) let c = (foreach match in matches foreach child1 in match.line.children foreach child2 in child1.children select child2.text) let newBlocks = a + b + c select newBlocks);
fixBlocks(blocks) = foreach line in blocks select replaceMatches(line, "\\b\\s\\b", "-");
normalizeBlocks(blocks) = foreach line in blocks let var_count = findTokenCount(line) select if var_count == 3 then patternMatch(line, pattern3) else if var_count == 4 then patternMatch(line, pattern4) else if var_count == 5 then patternMatch(line, pattern5) else null : {item: String, serialNum: String, description: String};
foreach x in [0] let blocks = parseConfigBlocks(OS.UNKNOWN, output) let newBlocks = flattenBlocks(blocks) let fixBlocks = fixBlocks(newBlocks) let normalizeBlocks = normalizeBlocks(fixBlocks) foreach block in normalizeBlocks select { item: block.item, serialNo: block.serialNum, description: block.description }
Hope you enjoyed this post and want to see more like it please like. If you have any questions or observations please leave a comment. Have a great day.
parseLine(s, n) = if n == 3 then regexMatches(s, re3) else if n == 6 then regexMatches(s, re6) else if n == 7 then regexMatches(s, re7) else null : List<{string: String, start: Number, end: Number, data: {Item: String, SerialNo: String, Description: String}}>;
foreach x in parseConfigBlocks(OS.UNKNOWN, fixIndent(output)) let match1 = regexMatches(x.text, reTest) foreach match in match1 let tokenCount = findTokenCount(match.string) let d = (max(parseLine(match.string, tokenCount)))?.data select { Item: d?.Item, Serial: d?.SerialNo, Description: d?.Description, tokenDebug: tokenCount }
Thanks to @musa for help with the regex expressions.